В задаче рассматриваются методы поиска текста в массиве, включая прямой поиск и предварительную обработку текста с созданием индекса. Обсуждаются плюсы и минусы каждого подхода, включая релевантность.
check_circle
Подробное решение
Вот краткое изложение информации с изображений, оформленное для удобного переписывания в тетрадь:
***
Таким способом в большом текстовом массиве можно находить упоминания тех или иных слов, адреса, номера телефонов и другие элементы.
* **Плюсы:**
* Поиск можно осуществлять сразу, без предварительной обработки.
* **Минусы:**
* Поиск затруднителен, если текст хранится в разных местах.
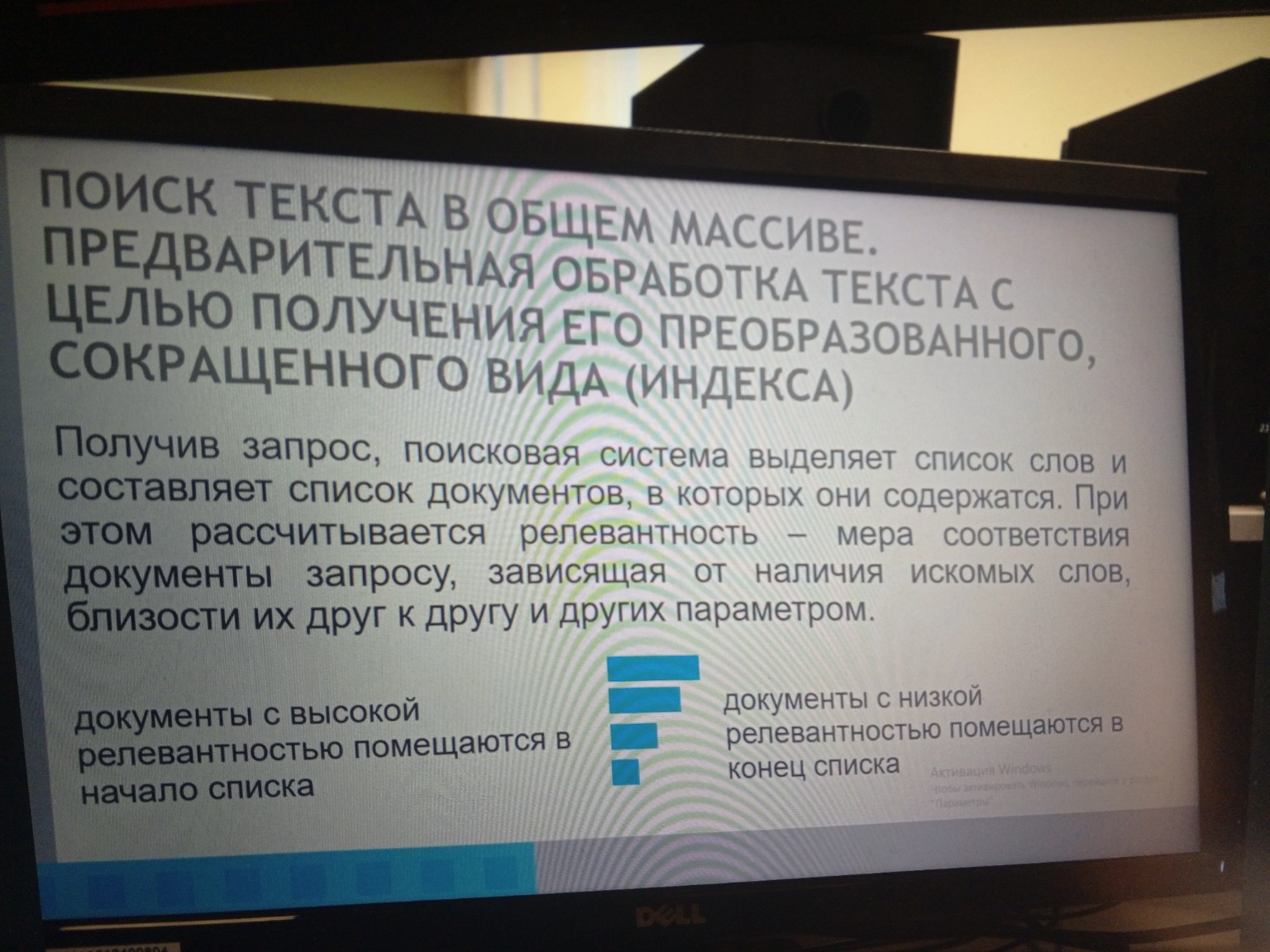
2. Предварительная обработка текста с целью получения его преобразованного, сокращенного вида (индекса)
Получив запрос, поисковая система выделяет список слов и составляет список документов, в которых они содержатся. При этом рассчитывается **релевантность** — мера соответствия документы запросу, зависящая от наличия искомых слов, близости их друг к другу и других параметров.
* Документы с высокой релевантностью помещаются в начало списка.
* Документы с низкой релевантностью помещаются в конец списка.
***