Реши задачу: Кратко Реши задачу: Кратко Реши задачу: Чуть больше
Нажмите для увеличения
lightbulbКраткий ответ
Решение задачи включает в себя поиск фрагмента текста, соответствующего заданному образцу. Метод позволяет находить упоминания определенных слов, адресов, номеров телефонов и других специфических элементов в больших объемах текста.
check_circle
Подробное решение
Хорошо, вот чуть более развернутое изложение, сохраняя удобство для переписывания в тетрадь:
***
Этот метод позволяет находить конкретные фрагменты текста, которые соответствуют заданному образцу.
* **Что можно найти:** Упоминания определённых слов, адреса, номера телефонов, даты, имена и другие специфические элементы в больших объёмах текста.
* **Преимущества:**
* Поиск можно начать немедленно, без необходимости какой-либо предварительной подготовки или обработки всего текстового массива. Это экономит время на этапе подготовки.
* **Недостатки:**
* Процесс поиска может быть значительно затруднён, если искомый текст или его части хранятся в разных местах, файлах или базах данных, что требует последовательного перебора всех возможных источников.
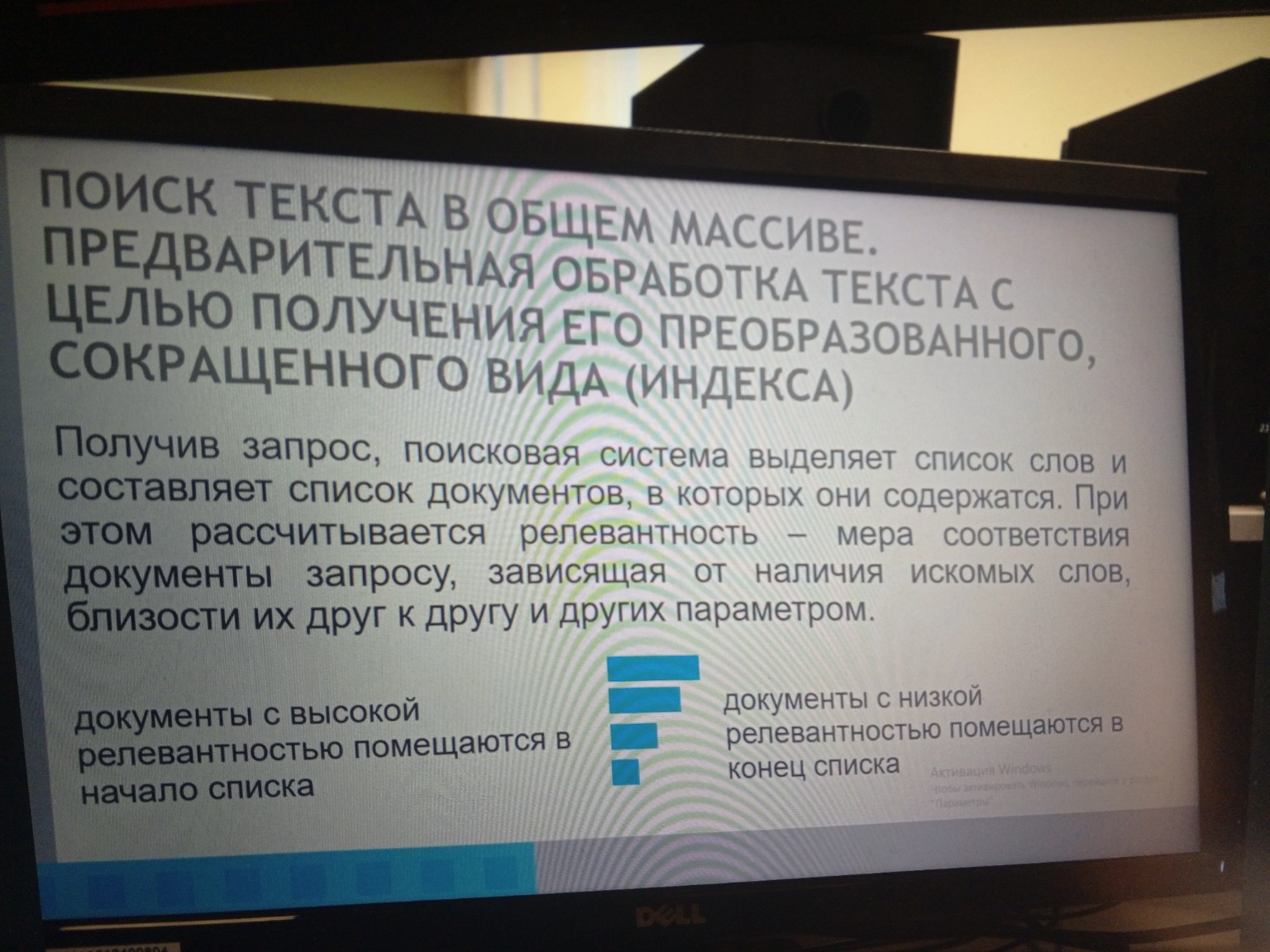
2. Предварительная обработка текста с целью получения его преобразованного, сокращенного вида (индекса)
Этот метод включает создание специального индекса для всего текстового массива, что значительно ускоряет последующий поиск.
* **Как это работает:**
1. Поисковая система получает запрос от пользователя.
2. Система анализирует запрос, выделяет из него ключевые слова.
3. На основе этих ключевых слов формируется список документов, в которых они содержатся.
4. Для каждого найденного документа рассчитывается **релевантность**.
* **Что такое релевантность:** Это мера того, насколько документ соответствует поисковому запросу. Она определяется по нескольким параметрам:
* Наличие всех искомых слов в документе.
* Частота их упоминания.
* Близость этих слов друг к другу в тексте.
* Другие факторы, такие как расположение слов (например, в заголовке или основном тексте).
* **Результат:**
* Документы, которые имеют высокую релевантность (то есть максимально соответствуют запросу), помещаются в начало списка результатов поиска.
* Документы с низкой релевантностью (менее соответствующие запросу) располагаются в конце списка.
***