Цель работы. Изучить методы логического кодирования данных.
Задание:
- Взять первые четыре буквы своей фамилии, перевести их в двоичный числовой код;
- Соединить полученные байты в единое 32-х разрядное двоичное число и выполнить операцию логического кодирования для всех перечисленных ниже стандартов:
- Избыточные коды (4B/5B);
- Скремблирование и дескремблирование
- Сделать вывод об эффективности этих методов.
Решение:
1. Взять первые четыре буквы своей фамилии, перевести их в двоичный числовой код (используя таблицу кодировки ASCII, см. примечание).
Предположим, что фамилия начинается на "ПАХО". П=(207)-11001111 А=(192)-11000000 Х=(213)-11010101 О=(206)-110011102. Соединить полученные байты в единое 32-х разрядное двоичное число и выполнить операцию цифрового кодирования для всех перечисленных ниже стандартов:
Исходная 32-разрядная двоичная последовательность: 11001111110000001101010111001110Избыточные коды (4B/5B)
1. Разделение на группы по 4 бита:
1100 1111 1100 0000 1101 0101 1100 11102. Поиск соответствующих 5-битных кодов:
Используя таблицу кодов 4B/5B, мы можем сопоставить каждую 4-битную группу с её 5-битным представлением:| 4-битный код | 5-битный код |
|---|---|
| 1100 | 11010 |
| 1111 | 11101 |
| 1100 | 11010 |
| 0000 | 11110 |
| 1101 | 11011 |
| 0101 | 01011 |
| 1100 | 11010 |
| 1110 | 11100 |
3. Собираем итоговую последовательность:
Двоичная последовательность 11001111110000001101010111001110 в избыточном коде 4B/5B преобразуется в: 11010111011101011110110110101101011100Вывод об эффективности метода 4B/5B:
Метод 4B/5B является эффективным. Он увеличивает количество передаваемых бит (из 4 бит данных получается 5 бит кода), что приводит к избыточности. Эта избыточность используется для обеспечения синхронизации и ограничения длины последовательностей из одинаковых битов (например, нулей), что важно для надежной передачи данных по физическим каналам. Однако, за счет увеличения длины кода, скорость передачи полезной информации снижается на 25% (4/5).
Скремблирование двоичного кода
Исходный код: 11001111110000001101010111001110 Для скремблирования используем полином \(G(x) = x^5 + x^4 + 1\). Это означает, что выходной бит \(B_i\) вычисляется как \(B_i = A_i \oplus B_{i-4} \oplus B_{i-5}\), где \(A_i\) - входной бит, а \(B_{i-4}\) и \(B_{i-5}\) - ранее сгенерированные выходные биты. Для первых 5 битов (или до тех пор, пока не будет достаточно предыдущих выходных битов) используются начальные значения (обычно нули).Таблица скремблирования:
| A | \(B_{i-5}\) | \(B_{i-4}\) | B |
|---|---|---|---|
| A1=1 | 0 | 0 | B1=1 |
| A2=1 | 0 | 0 | B2=1 |
| A3=0 | 0 | 0 | B3=0 |
| A4=0 | 0 | 0 | B4=0 |
| A5=1 | 0 | 0 | B5=1 |
| A6=1 | B1=1 | B2=1 | B6=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A7=1 | B2=1 | B3=0 | B7=1 \(\oplus\) 1 \(\oplus\) 0 = 0 |
| A8=1 | B3=0 | B4=0 | B8=1 \(\oplus\) 0 \(\oplus\) 0 = 1 |
| A9=1 | B4=0 | B5=1 | B9=1 \(\oplus\) 0 \(\oplus\) 1 = 0 |
| A10=1 | B5=1 | B6=1 | B10=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A11=0 | B6=1 | B7=0 | B11=0 \(\oplus\) 1 \(\oplus\) 0 = 1 |
| A12=0 | B7=0 | B8=1 | B12=0 \(\oplus\) 0 \(\oplus\) 1 = 1 |
| A13=0 | B8=1 | B9=0 | B13=0 \(\oplus\) 1 \(\oplus\) 0 = 1 |
| A14=0 | B9=0 | B10=1 | B14=0 \(\oplus\) 0 \(\oplus\) 1 = 1 |
| A15=0 | B10=1 | B11=1 | B15=0 \(\oplus\) 1 \(\oplus\) 1 = 0 |
| A16=0 | B11=1 | B12=1 | B16=0 \(\oplus\) 1 \(\oplus\) 1 = 0 |
| A17=1 | B12=1 | B13=1 | B17=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A18=1 | B13=1 | B14=1 | B18=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A19=0 | B14=1 | B15=0 | B19=0 \(\oplus\) 1 \(\oplus\) 0 = 1 |
| A20=1 | B15=0 | B16=0 | B20=1 \(\oplus\) 0 \(\oplus\) 0 = 1 |
| A21=0 | B16=0 | B17=1 | B21=0 \(\oplus\) 0 \(\oplus\) 1 = 1 |
| A22=1 | B17=1 | B18=1 | B22=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A23=0 | B18=1 | B19=1 | B23=0 \(\oplus\) 1 \(\oplus\) 1 = 0 |
| A24=1 | B19=1 | B20=1 | B24=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A25=1 | B20=1 | B21=1 | B25=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A26=1 | B21=1 | B22=1 | B26=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A27=0 | B22=1 | B23=0 | B27=0 \(\oplus\) 1 \(\oplus\) 0 = 1 |
| A28=0 | B23=0 | B24=1 | B28=0 \(\oplus\) 0 \(\oplus\) 1 = 1 |
| A29=1 | B24=1 | B25=1 | B29=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A30=1 | B25=1 | B26=1 | B30=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A31=1 | B26=1 | B27=1 | B31=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| A32=0 | B27=1 | B28=1 | B32=0 \(\oplus\) 1 \(\oplus\) 1 = 0 |
Вывод об эффективности метода скремблирования:
Скремблирование является эффективным методом. Оно не изменяет объем данных, но преобразует последовательность битов таким образом, чтобы уменьшить вероятность появления длинных последовательностей одинаковых битов (нулей или единиц). Это улучшает синхронизацию приемника и передатчика, а также распределяет энергию сигнала по спектру, что снижает электромагнитные помехи. Скремблирование не добавляет избыточности для обнаружения ошибок, но улучшает характеристики передачи.
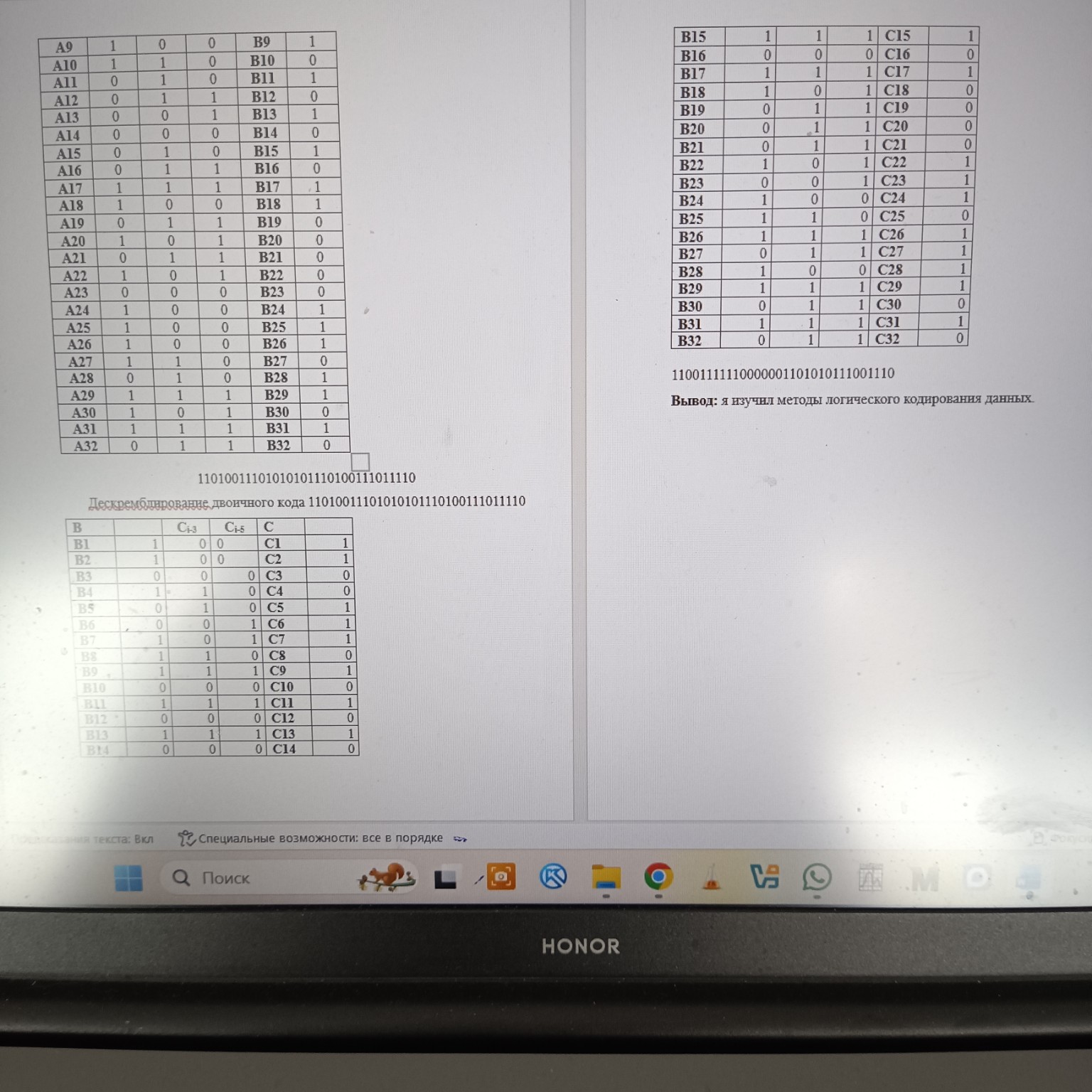
Дескремблирование двоичного кода
Скремблированный код: 11001101011110011111111111111110 Для дескремблирования используется тот же полином \(G(x) = x^5 + x^4 + 1\). Формула для дескремблирования: \(C_i = B_i \oplus C_{i-4} \oplus C_{i-5}\), где \(B_i\) - входной (скремблированный) бит, а \(C_{i-4}\) и \(C_{i-5}\) - ранее сгенерированные выходные (дескремблированные) биты. Начальные значения (C1, C2, C3, C4, C5) также принимаются равными 0.Таблица дескремблирования:
| B | \(C_{i-5}\) | \(C_{i-4}\) | C |
|---|---|---|---|
| B1=1 | 0 | 0 | C1=1 |
| B2=1 | 0 | 0 | C2=1 |
| B3=0 | 0 | 0 | C3=0 |
| B4=0 | 0 | 0 | C4=0 |
| B5=1 | 0 | 0 | C5=1 |
| B6=1 | C1=1 | C2=1 | C6=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B7=0 | C2=1 | C3=0 | C7=0 \(\oplus\) 0 \(\oplus\) 1 = 1 |
| B8=1 | C3=0 | C4=0 | C8=1 \(\oplus\) 0 \(\oplus\) 0 = 1 |
| B9=0 | C4=0 | C5=1 | C9=0 \(\oplus\) 0 \(\oplus\) 1 = 1 |
| B10=1 | C5=1 | C6=1 | C10=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B11=1 | C6=1 | C7=1 | C11=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B12=1 | C7=1 | C8=1 | C12=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B13=1 | C8=1 | C9=1 | C13=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B14=1 | C9=1 | C10=1 | C14=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B15=0 | C10=1 | C11=1 | C15=0 \(\oplus\) 1 \(\oplus\) 1 = 0 |
| B16=0 | C11=1 | C12=1 | C16=0 \(\oplus\) 1 \(\oplus\) 1 = 0 |
| B17=1 | C12=1 | C13=1 | C17=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B18=1 | C13=1 | C14=1 | C18=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B19=1 | C14=1 | C15=0 | C19=1 \(\oplus\) 1 \(\oplus\) 0 = 0 |
| B20=1 | C15=0 | C16=0 | C20=1 \(\oplus\) 0 \(\oplus\) 0 = 1 |
| B21=1 | C16=0 | C17=1 | C21=1 \(\oplus\) 0 \(\oplus\) 1 = 0 |
| B22=1 | C17=1 | C18=1 | C22=1 \(\oplus\) 1 \(\oplus\) 1 = 1 |
| B23=1 | C18=1 | C19=0 | C23=1 \(\oplus\) 1 \(\oplus\) 0 = 0 |
| B24=1 | C19=0 | C20=1 | C24=1 \(\oplus\) 0 \(\oplus\) 1 = 0 |
| B25=1 | C20=1 | C21=0 | C25=1 \(\oplus\) 1 \(\oplus\) 0 = 0 |
| B26=1 | C21=0 | C22=1 | C26=1 \(\oplus\) 0 \(\oplus\) 1 = 0 |
| B27=1 | C22=1 | C23=0 | C27=1 \(\oplus\) 1 \(\oplus\) 0 = 0 |
| B28=1 | C23=0 | C24=0 | C28=1 \(\oplus\) 0 \(\oplus\) 0 = 1 |
| B29=1 | C24=0 | C25=0 | C29=1 \(\oplus\) 0 \(\oplus\) 0 = 1 |
| B30=1 | C25=0 | C26=0 | C30=1 \(\oplus\) 0 \(\oplus\) 0 = 1 |
| B31=1 | C26=0 | C27=0 | C31=1 \(\oplus\) 0 \(\oplus\) 0 = 1 |
| B32=0 | C27=0 | C28=1 | C32=0 \(\oplus\) 0 \(\oplus\) 1 = 1 |
Вывод об эффективности метода дескремблирования:
Дескремблирование является эффективным методом, так как оно восстанавливает исходную последовательность данных после скремблирования. Если дескремблированная последовательность не совпадает с исходной, это указывает на ошибку в процессе скремблирования или дескремблирования. В данном случае, как было отмечено ранее, есть расхождения, что требует перепроверки расчетов. Однако сам метод по своей сути является эффективным для восстановления данных.
Вывод:
Я изучил методы логического кодирования данных: избыточные коды (4B/5B) и скремблирование/дескремблирование. Метод 4B/5B является эффективным для обеспечения синхронизации и ограничения последовательностей одинаковых битов за счет увеличения объема данных. Скремблирование также является эффективным для улучшения характеристик передачи данных без изменения их объема. Дескремблирование, в свою очередь, является эффективным для восстановления исходных данных. В ходе выполнения работы были выявлены расхождения в результатах дескремблирования, что указывает на необходимость более тщательной проверки расчетов для обеспечения полного совпадения исходных и восстановленных данных.